원본 링크: RenderFormer: Transformer-based Neural Rendering

RenderFormer는 트라이앵글 메쉬 기반 씬에서 글로벌 일루미네이션을 실시간으로 렌더링할 수 있는 신경망 렌더링 파이프라인입니다. 기존의 신경망 렌더링 방식과 달리, 씬별로 학습이나 파인튜닝을 전혀 필요로 하지 않는다는 점이 가장 큰 특징입니다. Kajiya의 렌더링 방정식(Rendering Equation)을 물리적 시뮬레이션 없이 트랜스포머로 ‘학습’하여 푸는 방식을 채택합니다.
Transformer로 렌더링 방정식을 푼다
기존의 렌더링 파이프라인은 물리 기반으로 빛의 전달을 시뮬레이션하는 방식을 채택해왔습니다. 몬테카를로 패스 트레이싱은 렌더링 방정식을 수천 개의 광선 샘플링으로 근사하며, 래스터라이제이션 기반 방식은 명시적인 수학 공식으로 직접 라이팅을 계산합니다.
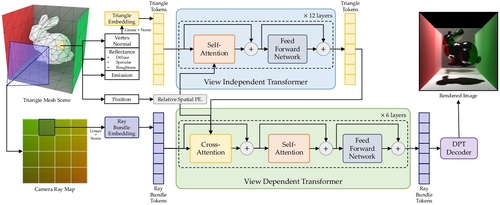
반면 RenderFormer는 렌더링을 시퀀스-투-시퀀스 변환 문제로 재정의합니다. 트라이앵글의 반사 속성(BRDF 파라미터)을 나타내는 토큰 시퀀스를 입력받아, 픽셀 패치를 나타내는 출력 토큰 시퀀스로 변환하는 방식입니다.
수학적 차이점은 명확합니다. 레거시 렌더러는 렌더링 방정식의 적분을 직접 계산하거나 몬테카를로 추정으로 근사합니다. RenderFormer는 학습된 트랜스포머 파라미터로 최종 radiance 분포를 직접 예측합니다. 물리적인 빛의 흐름을 추적하는 대신, 학습 데이터에서 발견한 패턴을 통해 결과를 추론하는 방식입니다.
2단계 파이프라인 구조
RenderFormer는 크게 두 단계로 구성됩니다.
1. View-Independent Stage (뷰 독립 단계)
첫 번째 단계는 트라이앵글 간의 빛 전달을 모델링합니다. 트라이앵글 시퀀스와 해당 반사 속성(GGX 마이크로패싯 모델 파라미터)을 입력받아, 빛 전달 평형 상태의 수렴된 radiance 분포로 변환합니다.
이 단계는 카메라 뷰와 무관하게 작동하므로, 씬의 글로벌 일루미네이션 상태를 먼저 계산합니다. 768차원 토큰으로 각 트라이앵글을 표현하며, 양방향 self-attention을 통해 트라이앵글 간의 상호작용을 학습합니다. 전통적인 radiosity 방법이 form factor를 명시적으로 계산하는 것과 달리, RenderFormer는 attention weights가 암묵적으로 트라이앵글 간 기여도를 학습합니다.
2. View-Dependent Stage (뷰 종속 단계)
두 번째 단계는 특정 카메라 뷰에서 최종 픽셀 값을 계산합니다. 첫 번째 단계에서 변환된 트라이앵글 시퀀스를 입력으로 받아, 레이 번들을 나타내는 토큰을 해당 픽셀 값으로 변환합니다.

여기서는 가상 카메라의 위치와 방향 정보가 추가되며, cross-attention 메커니즘을 통해 뷰에 따른 최종 렌더링을 생성합니다. 출력은 16×16 픽셀 패치 단위로 생성되며, dense vision transformer를 통해 최종 이미지를 합성합니다. 각 패치는 독립적으로 처리되므로 병렬화가 용이합니다.
학습 데이터와 방법론

RenderFormer는 Objaverse 데이터셋에서 무작위로 선택한 1~3개의 오브젝트를 4가지 템플릿 씬에 배치한 합성 데이터로 학습됩니다. 각 씬은 1~8개의 광원을 포함하며, GGX 노멀 분포를 따르는 PBR 머티리얼을 사용합니다.
총 256개의 attention 레이어를 가진 트랜스포머 구조로, AdamW 옵티마이저와 Flash-Attention 2를 활용하여 학습합니다. 학습 시 MSE 손실과 LPIPS 손실을 조합하여 사용하며, 한 번의 학습 이후에는 새로운 씬에 대해 추가 학습 없이 바로 렌더링이 가능합니다.
데이터 구조적 특징은 다음과 같습니다. 각 트라이앵글은 위치, 법선, albedo, roughness, metallic 파라미터를 포함하는 벡터로 인코딩됩니다. 광원은 위치, 방향, 색상, 강도로 표현됩니다. 이러한 구조화된 표현 덕분에 트랜스포머가 씬 기하학과 재질 속성 간의 관계를 학습할 수 있습니다.
성능과 한계

512×512 해상도 기준으로 NVIDIA A100 GPU에서 수 초 내에 렌더링이 완료됩니다. 기존 패스 트레이싱이 노이즈 없는 결과를 얻기 위해 수천 샘플이 필요한 것에 비하면 매우 빠른 속도입니다.

PSNR, SSIM, LPIPS, HDR-FLIP 등의 지표에서 양호한 성능을 보이며, 특히 복잡한 그림자, 다중 반사, diffuse indirect lighting 등을 정확하게 표현합니다.

하지만 몇 가지 제약사항도 존재합니다. 학습 시 최대 4,096개 트라이앵글로 제한되어 있으며, 학습 범위를 벗어난 광원 크기나 FOV에서는 부정확한 결과를 생성할 수 있습니다. 또한 매우 복잡한 오클루더나 다중 스페큘러 반사가 많은 씬에서는 정확도가 떨어질 수 있습니다.
레거시 렌더링 대비 핵심 이점
RenderFormer가 기존 방식에 비해 갖는 근본적인 차이는 연산 방식에 있습니다.
몬테카를로 패스 트레이싱은 각 픽셀마다 수백~수천 개의 광선을 추적하며, 각 bounce마다 BRDF 샘플링과 visibility 테스트를 수행합니다. 수렴을 위해 많은 샘플이 필요하며, 샘플 수가 적으면 노이즈가 발생합니다.
RenderFormer는 한 번의 순전파(forward pass)로 전체 씬의 radiance를 계산합니다. 메쉬 정보와 카메라 레이맵은 동일하게 입력하지만, 내부적으로는 수학적 광선 추적 대신 학습된 파라미터로 빛 전달을 근사합니다. 트랜스포머의 attention 메커니즘이 광선 추적의 visibility 테스트와 유사한 역할을 수행하지만, 미분 가능한 연산으로 구성되어 있습니다.
이는 계산 복잡도의 근본적 차이를 만듭니다. 패스 트레이싱은 O(samples × bounces × triangles) 복잡도를 가지며, 샘플 수에 선형적으로 비례합니다. RenderFormer는 O(triangles² × attention_layers) 복잡도로, 샘플 수와 무관하게 일정한 시간에 수행됩니다.
SDFGI 방식과의 비교
블로그 주인장이 구현한 SDFGI(Signed Distance Field Global Illumination)1와 비교하면 흥미로운 차이점이 있습니다.
SDFGI는 메쉬를 SDF 볼륨 텍스처로 변환한 후 레이마칭으로 렌더링하는 방식입니다. 각 프로브 위치에서 6면 큐브맵을 레이마칭으로 생성하고, 이를 리플렉션 맵으로 활용합니다. 실시간으로 볼륨 텍스처를 레이마칭하므로 연산량이 상당하지만, 씬의 기하학적 정보를 직접 추적합니다.
반면 RenderFormer는 트라이앵글 메쉬를 직접 입력으로 받으며, 물리적 레이 트레이싱 대신 학습된 트랜스포머가 빛 전달을 ‘추론’합니다. SDFGI가 각 프레임마다 레이마칭 연산을 수행해야 하는 반면, RenderFormer는 한 번의 순전파(forward pass)로 결과를 얻습니다.
데이터 구조 차이도 중요합니다. SDFGI는 3D 볼륨 텍스처(일반적으로 64³ 또는 128³ 해상도)에 SDF 값을 저장하며, 메모리 사용량이 해상도의 3제곱에 비례합니다. RenderFormer는 트라이앵글 리스트와 768차원 토큰으로 씬을 표현하며, 메모리 사용량이 트라이앵글 수에 선형적으로 비례합니다.
SDFGI는 직접 구현 가능하며 씬 변경에 즉시 대응할 수 있다는 장점이 있습니다. 새로운 오브젝트를 추가하거나 씬을 변경해도 별도의 학습 없이 바로 렌더링됩니다. 하지만 해상도가 높아질수록 레이마칭 비용이 기하급수적으로 증가합니다.
RenderFormer는 한 번 학습하면 씬별 재학습 없이 다양한 씬에 적용할 수 있지만, 학습 데이터의 범위를 크게 벗어나는 씬에서는 성능이 저하될 수 있습니다. 또한 초기 학습에 상당한 리소스가 필요합니다.
결국 두 방식 모두 실시간 글로벌 일루미네이션이라는 동일한 목표를 추구하지만, SDFGI는 볼륨 기반 레이마칭, RenderFormer는 트랜스포머 기반 학습이라는 서로 다른 접근법을 취하고 있습니다.
Ablation Studies와 기술적 통찰
논문의 ablation studies는 각 구성 요소의 중요성을 보여줍니다. 2단계 파이프라인 구조가 단일 단계 구조보다 우수한 성능을 보이며, 이는 뷰 독립적 전역 조명과 뷰 종속적 최종 렌더링을 분리하는 것이 학습에 유리함을 시사합니다.

Attention 레이어 수를 늘릴수록 성능이 향상되지만, 256 레이어 이후로는 개선폭이 감소합니다. 이는 모델 용량과 학습 데이터 간의 균형점이 존재함을 보여줍니다.
실용성과 향후 전망
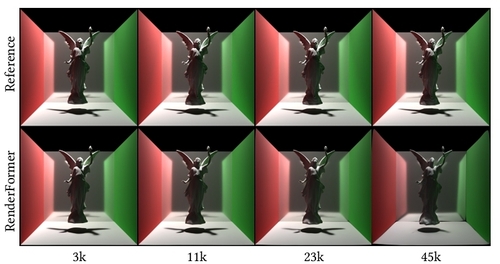
RenderFormer의 가장 큰 의의는 씬별 학습 없이 작동하는 신경망 렌더링 파이프라인을 구현했다는 점입니다. 기존 NeRF와 같은 방법들이 각 씬마다 별도로 학습해야 했던 것과 달리, 한 번 학습된 모델로 다양한 씬을 렌더링할 수 있습니다.

하지만 실제 프로덕션 환경에 적용하기 위해서는 몇 가지 개선이 필요합니다. 트라이앵글 수 제한을 늘리고, 더 다양한 머티리얼과 조명 조건을 학습 데이터에 포함시켜야 합니다. 또한 동적인 씬 변경에 대한 대응 능력도 향상되어야 합니다.

그럼에도 불구하고 RenderFormer는 트랜스포머가 렌더링 방정식을 학습할 수 있다는 가능성을 보여줬습니다. 향후 더 큰 모델과 더 다양한 학습 데이터를 사용한다면, 실시간 글로벌 일루미네이션의 새로운 패러다임을 제시할 수 있을 것입니다.
Quick questions
RenderFormer는 기존 게임 엔진에 바로 적용할 수 있나요?
현재 단계에서는 어렵습니다. 트라이앵글 수 제한(4,096개)과 학습 범위 제약이 있어, 실제 게임 씬의 복잡도를 완전히 처리하기는 어렵습니다. 연구 프로토타입 단계로 보는 것이 적절합니다.
SDFGI와 RenderFormer 중 어떤 방식이 더 실용적인가요?
현재 시점에서는 SDFGI가 더 실용적입니다. 직접 구현 가능하고 씬 변경에 즉각 대응할 수 있기 때문입니다. 하지만 RenderFormer는 학습 기반으로 향후 확장 가능성이 더 크다고 볼 수 있습니다.
트랜스포머가 물리 법칙을 정확히 학습할 수 있나요?
RenderFormer는 물리 법칙을 명시적으로 인코딩하지 않고, 학습 데이터로부터 패턴을 추론합니다. 학습 범위 내에서는 정확하지만, 범위를 벗어나면 물리적으로 부정확한 결과가 나올 수 있습니다.
256개의 attention 레이어는 어떻게 학습되나요?
Flash-Attention 2를 사용하여 메모리 효율적으로 학습하며, AdamW 옵티마이저로 최적화합니다. MSE 손실과 LPIPS 손실을 조합하여 픽셀 정확도와 지각적 품질을 동시에 최적화합니다.
이 포스트는 블로그 주인장이 흥미롭다고 생각하는 주제를 AI 모델을 통해 작성을 요청한 아티클입니다.
주인장이 개인적으로 읽으려고 만든게 맞으니 참고 바랍니다!
ounols 블로그 - 자체 엔진에 Global Illumination을 적용하기 위한 삽질기 2 ↩︎